[SQL] Basic SQL
SQL 기초 정리
SQL문의 종류
DDL (Data Definition Language, 데이터 정의어)
- CREATE: 객체 생성
- DROP: 객체 제거
- ALTER: 객체 변경
- TRUCATE TABLE: 테이블에 있는 모든 데이터 삭제
- RENAME: 객체 이름 변경
DML (Data Manipulation Language, 데이터 조작어)
- SELECT: 테이블이나 뷰에서 데이터 조회
- INSERT: 데이터 입력
- UPDATE: 기존에 저장된 데이터 수정
- DELETE: 테이블에 있는 데이터 삭제
- MERGE: 조건에 따라 INSERT와 UPDATE수행
TCL (Transaction Control Language, 트랜잭션 제어어)
- COMMIT: DML로 변경된 데이터를 DB에 적용
- ROLLBACK: DML로 변경된 데이터를 변경 이전 상태로 rollback
알아두어야 할 기본 코드
Oracle, Mysql, Postgre, BigQuery등 다양한 sql에서 문법이나 명령어가 조금씩 다를 수 있으므로 그때그때 공부해두기
CHECK AND USE
SHOW DATABASES; -- 서버에 어떤 DB가 있는지
USE DatabaseName; -- 사용할 DB지정
SHOW TABLE -- DB의 테이블 이름 보기
SHOW TABLE STATUS -- DB의 테이블 정보 조회 (e.g. 엔진버전, row개수)
DESCRIBE tablename -- 테이블에서 각 열(field)에 대한 정보 조회
SELECT
-- sql에서 주석 다는법
-- 단일 /*여러줄*/
-- field는 그자체 혹은 연산도 가능 ex) field+field, field/10
SELECT * FROM tablename; -- 테이블 전체 조회
SELECT * FROM table1, table2; -- 테이블1,2 전체조회
SELECT field1 AS alias_name, field2 FROM table1, table2; -- 테이블 1,2에서 컬럼조회, alias로 컬럼명 변경
SELECT f1 + f2 - 4 FROM table1 -- 컬럼에 사칙연산 적용 +, - , *, /, %(나머지)
SELECT ... FROM ... WHERE condition -- where문을 사용하여 조건에 맞는 데이터 조회
SELECT AVG(field1) FROM tabl1 WHERE condition GROUP BY field; -- GROUP BY를 이용하여 데이터 집계
SELECT f1, f2, COUNT(1) FROM t1 GROUP BY f1,f2 -- f1,f2그룹별 row개수 까지 출력
SELECT ... FROM ... WHERE condition GROUP BY f1,f2 HAVING condition2; -- HAVING절은 GROUPBY절과 함께사용. 즉 copndition2는 집계된 데이터(f1,f2) 기준으로 조건 설정
SELECT f1, f2, SUM(f3) FROM t1 GROUP BY f1, f2 WITH ROLLUP -- WITH ROLLUP 총합 또는 중간합계가 필요할 경우
SELECT ... FROM ... WHERE condition ORDER BY field1, field2; -- 조회시 정렬적용 defalut 오름차순(Ascending)
SELECT ... FROM ... WHERE condition ORDER BY field1, field2 DESC; -- ASC|DESC 오름차순|내림차순
SELECT ... FROM ... WHERE condition LIMIT 10; -- LIMIT 조회건수 제한 상위N개만 조회
SELECT DISTINCT field1 FROM ... -- DISTINCT 유니크한 값조회(중복X), 두개 이상의 컬럼일 경우 unique pairs
Conditions
여러 조건 패턴
field1 = value1 -- value1 과 같은값 조회, 이외에도 조건연산자 >,<,>=,<= 등도 가능
field1 <>,!= value1 -- 같지 않은값 조회
field1 LIKE 'wildcard' -- '_'는 한글자 '%'는 모든글자 (%A%-중간에A포함, %A-A로끝나느문자,A%-A로 시작하는 문자 등으로 검색)
field1 IS NULL -- null value만
field1 IS NOT NULL
field1 IN (value1, value2) -- 원하는 value1,value2를 포함하는 값 조회 e.g. city field에 'seoul','busan'만 조회, numeric,non-numeric가능
field1 NOT IN (value1, value2)
condition1 AND condition2
condition1 OR condition2
field BETWEEN value1 AND value10 -- value 1과 value 2 사이의 값들 조회
Wildcard
- LIKE: 대소문자 구분(case sensitive)(e.g. a와A는 다르다고 판단)
- ILIKE: 대소문자 구분x(case insensitive)(e.g. a와A는 동일하다 판단)
| LIKE Operator | Description |
|---|---|
| WHERE fieldname LIKE ‘a%’ | Finds any values that starts with “a” |
| WHERE fieldname LIKE ‘%a’ | Finds any values that ends with “a” |
| WHERE fieldname LIKE ‘%or%’ | Finds any values that have “or” in any position |
| WHERE fieldname LIKE ‘_r%’ | Finds any values that have “r” in the second position |
| WHERE fieldname LIKE ‘a__%’ | Finds any values that starts with “a” and are at least 3 characters in length |
| WHERE fieldname LIKE ‘a%o’ | Finds any values that starts with “a” and ends with “o” |
| WHERE fieldname LIKE ‘[acs]%’ | Finds any values that starts with “a” or “c” or “s” |
| WHERE fieldname LIKE ‘[a-g]%’ | Finds any values that starts with “a” to “g” not은 [!a-g] |
if
SELECT IF(field condition, 'value if true', 'value if false') as ... FROM ...
SELECT IFNULL(field,'value if null') ...
CASE
- 조건에 따라 값을 변환, CASE ~ END 로 하나의 column 생성한다 생각
SELECT field1
CASE
WHEN field2 condition1 THEN 'result1'
WHEN field2 condition2 THEN 'result2'
ELSE 'result3'
END AS case_col
FROM table1;
SELECT field1,
CASE
WHEN field2 condition1 AND field3 condition2 THEN 'result1'
ELSE NULL
END AS sample_case
FROM table1;
데이터 조인 및 집합
SELECT - JOIN
JOIN은 데이터베이스 내의 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현
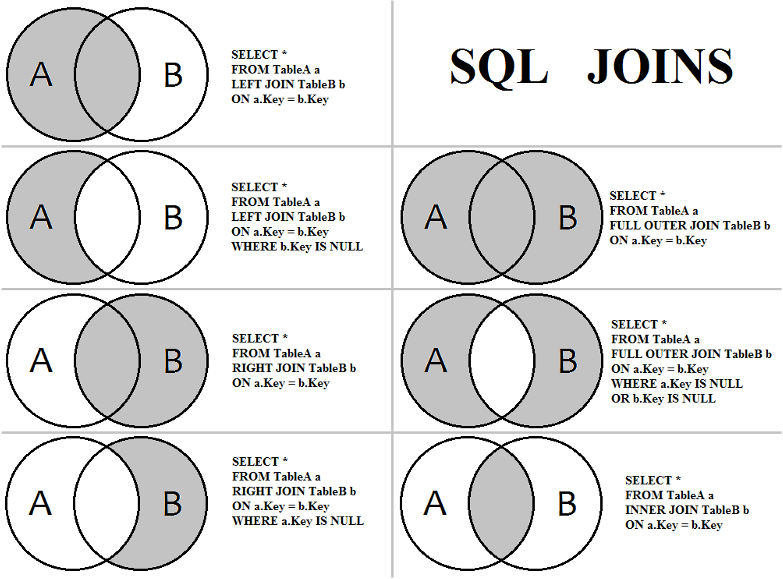
쉬운 이해를 위한 JOIN visualization by Patrik Spathon
SELECT ... FROM t1 LEFT JOIN t2 ON t1.Key = t2.Key --LEFT OUTER JOIN (A)
SELECT ... FROM t1 LEFT JOIN t2 ON t1.Key = t2.Key WHERE t2.key IS NULL --LEFT ANTI JOIN (A-B)
SELECT ... FROM t1 RIGHT JOIN t2 ON t1.Key = t2.Key --RIGHT OUTER JOIN (B)
SELECT ... FROM t1 RIGHT JOIN t2 ON t1.Key = t2.Key WHERE t1.key IS NULL --RIGHT ANTI JOIN (B-A)
SELECT ... FROM t1 FULL OUTER JOIN t2 ON t1.key = t2.key --FULL OUTER JOIN (A+B)
SELECT ... FROM t1 FULL OUTER JOIN t2 ON t1.key = t2.key WHERE t1.key IS NULL or t2.key IS NULL -- (A+B - (A&B))
SELECT ... FROM t1 INNER JOIN t2 ON t1.column_name = t2.column_name; --INNER JOIN(or JOIN) (A&B)
SELECT ... FROM t1
LEFT JOIN t2 ON t1.key = t2.key
LEFT JOIN t3 ON t1.key = t3.key
--Join with comparison operator or multiple keys 도 가능
SELECT ... FROM t1
LEFT JOIN t2 ON t1.key = t2.key AND t1.field1 > t2.field1 + 5
--Self join
SELECT t1.field1, t1.field2, ...
FROM table1 as t1
JOIN table1 as t1_1
ON t1.key = t1_1.key AND t1_1.field2 condition a
SELECT - UNION
UNION은 SELECT 문의 결과 데이터를 하나로 합쳐서 출력
- 컬럼의 갯수와 타입, 순서가 같아야 함
- UNION은 자동으로 distinct를 하여 중복을 제거
- 중복제거를 안하고 컬럼 데이터를 합치고 싶으면 UNION ALL을 사용.
- 또한 UNION을 이용하면 Full Outer Join을 구현.
SELECT ... FROM t1
UNION
SELECT ... FROM t2
-- 테이블 세로 결합
SELECT "t1" AS t1.id,... FROM t1
UNION ALL
SELECT "t2" AS t2.id,... FROM t2
SELECT - INTERSECT
교집합, 오직 종복 데이터만 추출
SELECT ... FROM t1
INTERSECT
SELECT ... FROM t2
SELECT - MINUS
차집합, 첫번째 쿼리에만 존재하는 데이터 조회
SELECT ... FROM t1
MINUS
SELECT ... FROM t2
함수
SELECT
함수(field1)
FROM table1;
문자 관련 함수
- 빈공간(space)도 문자열임!
| 함수 | 함수 | 함수 | |||
|---|---|---|---|---|---|
| LOWER | 소문자변환 | UPPER | 대문자변환 | INITCAP | 첫자 대문자 |
| SUBSTR(field1,시작위치,나타낼개수) | 문자열일부분선택,시작위치가 -시 뒤부터 | ||||
| REPLACE(‘찾을값’,’대체값’) | 특정문자열변환 | CONCAT(field1,field2) | 두문자열연결 | LENGTH | 문자열길이 |
| INSTR(field1,’값’) | 값의 위치 | LPAD(field1,자리수,’값’) | 왼쪽부터 지정한 자리수 보다 부족하면 ‘값’ 으로 채움 | RPAD | |
| LTRIM(field1,’값’) | 주어진 ‘값’왼쪽방향으로 제거 | RTRIM | TRIM | 공백제거 |
Using String Fuctions to Clean Data
-- LEFT 또는 RIGHT(string,나타낼개수) 왼쪽 또는 오른쪽부터 나타낼 str 수
SELECT LEFT(field1,10) FROM t1 -- field1에 앞부터 str 10개만
SELECT RIGHT(field1,10) FROM t1 -- field1에 뒤부터 str 10개
-- LENGTH(str) 문자열 길이(시간 포함)
SELECT RIGHT(field1, LENGTH(field2) - 11) FROM t1 -- 문자열길이를 return하기에 이런식으로도 사용 가능
-- TRIM() default: 좌우공백제거
-- TRIM(문자열 원본, "자를 문자") : ex TRIM("안녕하세요","하세요") -> "안녕"
-- TRIM(BOTH '제거할 문자' FROM field1) : 좌우 문자 제거
-- TRIM(LEADING FROM field1) : 좌측 제거
-- TRIM(TRAILING FROM field1) : 우측 제거
SELECT TRIM(BOTH 'example' FROM t1.field1) FROM t1
-- SUBSTR(field1,시작위치,나타낼개수): 문자열 일부분 선택, 시작위치가 -시 우측부터
SELECT SUBSTR(field1,5,10) FROM t1 -- field1의 문자열 5번째부터 10개 나타내기
-- CONCAT(field1,'str',field2....) 문자열 연결
SELECT CONCAT(CUS_ID,':',CUS_type) FROM Customer_Table
날짜 관련 함수
- 날짜도 문자열중 하나라고 생각하면 편함 SUBSTR등 사용이 가능함
| 함수 | 함수 | 함수 | |||
|---|---|---|---|---|---|
| NOW() | SYSDATE() | CURRENT_TIMESTAMP() | 현재 날짜와 시간 출력 | ||
| CURDATE() | 현재 날짜 출력 | CURTIME() | 현재 시간 출력 |
-- 기준:YEAR MONTH DAY HOUR MINUTE SECOND
SELECT DATE_FORMAT(DATETIME, '%Y-%M-%D') ... -- DATETIME을 20xx-xx-xx와 같이 출력
SELECT EXTRACT(YEAR FROM datefield) FROM t1 -- 필요한날짜만 출력
-- DATE_TRUNC() :TRUNC의 타임 버전, 명시된 시간 단위보다 더 작은 단위 숫자는 버림 ex) week이면 1월1일부터 시작한다면 1월6일까진 1월1일로
SELECT DATE_TRUNC('기준', datefield)
-- DATE_ADD & DATE_SUB(date INTERVAL value addunit)
-- addunit: YEAR QUARTER MONTH WEEK DAY HOUR MINUTE YEAR_MONTH DAY_HOUR...
SELECT DATE_ADD(datefield, INTERVAL 1 YEAR) FROM t1 -- 날짜 덧뺄셈
-- 또는
SELECT datefield + INTERVAL '5 MINUTE' FROM t1
NULL 관련 함수
| 함수 | |
|---|---|
| COALESCE(field1,0) | filed1에 null값 0으로 대체 |
SELECT COALESCE(field1,'fill value') FROM t1 --null이면 fill value로대체
SELECT COALESCE(field1,0) --null이면 0 으로 대체
숫자 관련 함수
| 함수 | 함수 | |||
|---|---|---|---|---|
| ROUND(field1,값) | ‘값’에 따라 반올림 | TRUNC() | 숫자버림 | |
| ABS() | 절대값 | POWER(X,Y) | X의 Y승 | |
| EXP() | e의거듭제곱계산 | LN(n) | n 의자연로그 값 계산 | |
| SQRT() | 양의제곱근 | SIGN() | 주어진 값의 음수,정수,0여부 -> -1,0,1. null은 null반환 | |
| greatest() | 최대값 | least() | 최소값 |
집계 함수
- aggregators only aggregate vertically
- MIN 은 최소값, earliest date, alphabet A에 가까운 값 출력
- AVG 는 numeric에서만 사용가능하며 null을 무시함, 즉 null값을 처리해야함 0,interpolate..
| 함수 | 함수 | 함수 | |||
|---|---|---|---|---|---|
| COUNT(1) or COUNT(*) | counting rows | SUM() | 합산,null은 0 취급 | AVG() | 평균 |
| COUNT(DISTINCT(col)) | 중복 제외 개수 | STDEV() | 표준편차 | VARIANCE() | 분산 |
| COUNT(col) | null제외 col row개수 | MIN() | 최소값 | MAX() | 최대값 |
윈도 함수
- 행 과 행 간의 관계를 정의하기 위해 제공되는 함수
- 집계 함수의 결과와 원래 값을 추가하여 나타낼 수 있음
- OVER 구문에 매개 변수 지정하지 않으면 테이블 전체의 집계함수 적용값이 리턴
- 매개변수에 PARTITION BY 컬럼이름 을 지정하면 해당 컬럼 값을 기반으로 그룹화 하고 집계 함수 적용
SELECT id, AVG(field1) OVER(), AVG(field1) OVER(PARTITION BY id ORDER BY 순서열) FROM t1
SELECT id, ROW_NUMBER() OVER (ORDER BY 순서열), -- 행번호, 순서열 순서로 유일한 순위값 1,2,3,4,5
RANK() OVER (ORDER BY 순서열), --중복가능 즉, 같은 순위 허용 1,2,3,3,5
DENSE_RANK() OVER (ORDER BY 순서열), -- 공동 순위가 있더라도 순차적으로 rank 1,2,3,3,4
LAG(열,n,결측치 채울 값) OVER (ORDER BY 순서열), -- 현재 행보다 위에 있는 행의 값 추출, n칸 미루기 | 위부터 하루 단위 날짜순이면 n=1, 하루 전 데이터
LEAD(열,n,결측치 채울 값) OVER (ORDER BY 순서열) -- 현재 행보다 아래에 있는 행의 값 추출, n칸 당기기 | 위부터 하루 단위 날짜순이면 n=1, 하루 후 데이터
FROM table1
-- NTILE(number of buckets)
SELECT field1,
duration_seconds,
NTILE(4) OVER
(PARTITION BY field1 ORDER BY duration_seconds)
AS quartile,
NTILE(5) OVER
(PARTITION BY field1 ORDER BY duration_seconds)
AS quintile,
NTILE(100) OVER
(PARTITION BY field1 ORDER BY duration_seconds)
AS percentile
FROM table1
ORDER BY field1, duration_seconds
| ROWS | 윈도우 지정 구문 |
| BETWEEM start AND end | 윈도우의 시작과 끝 위치 지정 |
| n PRECEDING | n행 앞 |
| n FOLLOWING | n행 뒤 |
| CURRENT ROW | 윈도우 시작위치가 현재 행(데이터가 추출된 현재 행) |
| UNBOUNDED PRECEDING | 윈도우 시작위치가 첫번째 행-이전 행 전부 |
| UNBOUNDED FOLLOWING | 윈도우 마지막위치가 마지막 행- 이후 행 전부 |
| FIRST_VALUE() | 가장 첫번째 레코드 추출 |
| LAST_VALUE() | 가장 마지막 레코드 추출 |
SELECT id, ROW_NUMBER() OVER(ORDER BY 순서열), -- ROW NUMBER COUNTING
SUM(filed1) OVER(ORDER BY 순서열 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW), -- 순서 상위부터 누계 계산
AVG(field1) OVER(ORDER BY 순서열 ROWS BETWEEN 1 PRECEDING and 1 FOLLOWING) -- 현재 행과 앞 뒤의 행 기반 평균 점수
SubQuery
쿼리문 안에 쿼리문을 서브쿼리라고함
| SELECT col1, (SELECT …) | 스칼라 서브쿼리(Scalar Sub Query): 하나의 컬럼처럼 사용 (표현 용도) |
| FROM (SELECT …) | 인라인 뷰(Inline View): 하나의 테이블처럼 사용 (테이블 대체 용도) |
WHERE col contition (SELECT …) |
일반 서브쿼리: 하나의 변수(상수)처럼 사용 (서브쿼리의 결과에 따라 달라지는 조건절) |
스칼라 서브쿼리 SELECT col1, (SELECT …)
- 메인 쿼리의 SELECT절에서 하나의 컬럼이나 표현식처럼 사용
- 스칼라 서브쿼리는 반환값이 하나(하나의 컬럼)이여야함
-- 테이블1과 테이블2의 field2가 같은 값에 대해서 테이블 2에서 field10 가져오기
SELECT t1.field1, t1.field2,(SELECT t2.field10
FROM table2 as t2
WHERE t1.field2 = t2.field2) as field10
FROM table1 as t1
인라인 뷰 FROM (SELECT …)
- 메인쿼리에 FROM 절에서 사용하는 서브쿼리
- 즉, 하나의 테이블 처럼 사용
SELECT t1.field1, t1.field2, subt.field5
FROM table1, (SELECT *
FROM table2 as t2, table3 as t3
WHERE t2.field11 = t3.field11 ) as subt
중첩 서브쿼리
where 절에서 condition(조건) 에 변수처럼 사용
단일 행 서브쿼리
- 서브쿼리 결과값이 하나일때
-
,=,<,!= 와 같은 연산자를 쓸시
SELECT * FROM table1 as t1
WHERE t1.field1 = (SELECT t2.field1
FROM table2 as t2
WHERE t2.field2 = value)
다중 행 서브쿼리
- 서브쿼리에서 반환되는 결과가 하나 이상인 경우
| IN | 메인쿼리의 비교조건이 서브쿼리 결과 중에서 하나라도 일치하는 값만추출 | |
| ANY,SOME | 메인쿼리의 비교조건이 서브쿼리의 검색결과와 하나 이상 일치하는 값추출 | >ANY면 서브쿼리 결과의 최소값보다 큰값들 |
| ALL | 메인쿼리의 비교조건이 서브쿼리 검색결과와 모두 일치하는 값 추출 | >ALL면 서브쿼리 결과의 최대값보다큰값들 |
| EXIST | 메인쿼리의 비교조건이 서브쿼리의 결과 중 만족하는 값이 하나라도 존재하면 값추출 |
SELECT *
FROM table1 as t1 WHERE t1.field1 IN (SELECT t2.field1
FROM table2 as t2, table3 as t3 WHERE t3.field5 > 1)
기타
CTE(Common Table Expression WITH 구문)
- 반복 되는 쿼리가 있을때 사용
- WITH 구문으로 임시 테이블처럼 사용
-- 1개의 임시 테이블
WITH 임시테이블명 AS (서브쿼리문 (SELECT ...))
SELECT ... FROM 임시테이블명
-- 2개 이상의 임시 테이블
WITH 임시테이블명1 AS (서브쿼리문 (SELECT절)),
임시테이블명2 AS (서브쿼리문 (SELECT절))
SELECT ... FROM 임시테이블명1, 임시테이블명2
연산자
| 연산자 | 설명 |
|---|---|
| + | 두 수나 날짜를 더함 |
| - | 두 수나 날짜를 뺌 |
| * | 두 수를 곱함 |
| / | 나눔 |
| % | 나머지 |
|| |
두 문자를 결합함 |
REPEAT
SET @number = 0; -- SET: 변수 선언 프로시져가 끝나도 계속 유지되는 변수 @변수
SELECT REPEAT('* ', @number := @number + 1) -- number에 1씩 누적 더함 := 는 대입 연산자
FROM INFORMATION_SCHEMA.TABLES
WHERE @number < 20 -- 20이하까지 반복
Create/Delete/Modify Table
Create
CREATE TABLE tablename (field1 type1, field2 type2);
CREATE TABLE tablename (field1 type1, field2 type2, INDEX (field1));
CREATE TABLE tablename (field1 type1, field2 type2, PRIMARY KEY (field1));
CREATE TABLE tablename (field1 type1, field2 type2, PRIMARY KEY (field1,field2));
CREATE TABLE tablename (fk_field1 type1, field2 type2, ...,
FOREIGN KEY (fk_field1) REFERENCES table2 (t2_fieldA))
[ON UPDATE|ON DELETE] [CASCADE|SET NULL]
CREATE TABLE table1 (fk_field1 type1, fk_field2 type2, ...,
FOREIGN KEY (fk_field1, fk_field2) REFERENCES table2 (t2_fieldA, t2_fieldB))
CREATE TABLE table1 IF NOT EXISTS;
CREATE TEMPORARY TABLE table1;
Drop
DROP TABLE tablename;
DROP TABLE IF EXISTS table;
DROP TABLE table1, table2, ...
Delete
DELETE FROM table1 / TRUNCATE table1
DELETE FROM table1 WHERE conditions
DELETE FROM table1, table2 FROM table1, table2 WHERE table1.id1 =
table2.id2 AND condition
Insert
INSERT INTO table1 (field1, field2...) -- 지정컬럼 기준
VALUES (value1, value2,...)
INSERT INTO table1 VALUES (value1...) -- 컬럼 순서별
INSERT INTO table2 (filed1, field2,...) -- 조회결과 다시 입력
SELECT fielnd1, field2,...
FROM table1
WHERE conditions;
Alter 테이블 수정
ALTER TABLE table MODIFY field1 type1 -- MODIFY 테이블 필드 타입 수정
ALTER TABLE table MODIFY field1 type1 NOT NULL ...
ALTER TABLE table CHANGE old_name_field1 new_name_field1 type1
ALTER TABLE table CHANGE old_name_field1 new_name_field1 type1 NOT NULL ...
ALTER TABLE table ALTER field1 SET DEFAULT ...
ALTER TABLE table ALTER field1 DROP DEFAULT
ALTER TABLE table ADD new_name_field1 type1 -- ADD 필드 추가
ALTER TABLE table ADD new_name_field1 type1 FIRST
ALTER TABLE table ADD new_name_field1 type1 AFTER another_field
ALTER TABLE table DROP field1
ALTER TABLE table ADD INDEX (field);
Change field order
ALTER TABLE table MODIFY field1 type1 FIRST
ALTER TABLE table MODIFY field1 type1 AFTER another_field
ALTER TABLE table CHANGE old_name_field1 new_name_field1 type1 FIRST
ALTER TABLE table CHANGE old_name_field1 new_name_field1 type1 AFTER another_field
Create/Open/Delete Database
CREATE DATABASE DatabaseName;
CREATE DATABASE DatabaseName CHARACTER SET utf8;
USE DatabaseName; -- USE로 새 데이터베이스 만들면 사용
DROP DATABASE DatabaseName;
ALTER DATABASE DatabaseName CHARACTER SET utf8;
Backup Database to SQL File, Restore from backip SQL File
mysqldump -u Username -p dbNameYouWant > databasename_backup.sql;
sql
- u Username -p dbNameYouWant < databasename_backup.sql;